Although NixOps is quite popular, its availability also leads to a bit of confusion with another tool. Some Nix users, in particular newbies, are suffering from this. The purpose of this blog post is to clear up that confusion.
NixOps
NixOps is something that is advertised as the "NixOS-based cloud deployment tool". It basically expands NixOS' (a Linux distribution built around the Nix package manager) approach of deploying a complete system configuration from a declarative specification to networks of machines and instantiates and provisions the required machines (e.g. in an IaaS cloud environment, such as Amazon EC2) automatically if requested.
A NixOps deployment process is driven by one or more network models that encapsulate multiple (partial) NixOS configurations. In a standard NixOps workflow, network models are typically split into a logical network model capturing settings that are machine independent and a physical network model capturing machine specific properties.
For example, the following code fragment is a logical network model consisting of three machines capturing the configuration properties of a Trac deployment, a web-based issue tracker system:
{
network.description = "Trac deployment";
storage =
{ pkgs, ... }:
{ services.nfs.server.enable = true;
services.nfs.server.exports = ''
/repos 192.168.1.0/255.255.255.0(rw,no_root_squash)
'';
services.nfs.server.createMountPoints = true;
};
postgresql =
{ pkgs, ... }:
{ services.postgresql.enable = true;
services.postgresql.package = pkgs.postgresql;
services.postgresql.enableTCPIP = true;
services.postgresql.authentication = ''
local all all trust
host all all 127.0.0.1/32 trust
host all all ::1/128 trust
host all all 192.168.1.0/24 trust
'';
};
webserver =
{ pkgs, ... }:
{ fileSystems = [
{ mountPoint = "/repos";
device = "storage:/repos";
fsType = "nfs";
}
];
services.httpd.enable = true;
services.httpd.adminAddr = "root@localhost";
services.httpd.extraSubservices = [
{ serviceType = "trac"; }
];
environment.systemPackages = [
pkgs.pythonPackages.trac
pkgs.subversion
];
};
}
The three machines in the above example have the following purpose:
- The first machine, named storage, is responsible for storing Subversion source code repositories in the following folder: /repos and makes the corresponding folder available as a NFS mount.
- The second machine, named postgresql, runs a PostgreSQL database server storing the tickets.
- The third machine, named webserver, runs the Apache HTTP server hosting the Trac web application front-end. Moreover, it mounts the /repos folder as a network file system connecting to the storage machine so that the Trac web application can view the Subversion repositories stored inside it.
The above specification can be considered a logical network model, because it captures the configuration we want to deploy, without any machine specific characteristics. Regardless of what kind of machine we intend deploy, we want these services to be available.
However, a NixOS configuration cannot be deployed without any machine specific settings. These remaining settings can be specified by writing a second model, the physical network model, capturing these:
{
storage =
{ pkgs, ...}:
{ boot.loader.grub.version = 2;
boot.loader.grub.device = "/dev/sda";
fileSystems = [
{ mountPoint = "/";
label = "root";
}
];
swapDevices = [
{ label = "swap"; }
];
networking.hostName = "storage";
};
postgresql = ...
webserver = ...
}
The above partial network model specifies the following physical characteristics for the storage machine:
- GRUB version 2 should be used as bootloader and should installed on the MBR of the hard drive partition: /dev/sda.
- The hard drive partition with label: root should be mounted as root partition.
- The hard drive partition with label: swap should be mounted as swap partition.
- The hostname of the system should be: 'storage'
By invoking NixOps with the two network models shown earlier as parameters, we can create a NixOps deployment -- an environment containing a set of machines that belong together:
$ nixops create ./network-logical.nix ./network-physical.nix -d test
The above command creates a deployment named: test. We can run the following command to actually deploy the system configurations:
$ nixops deploy -d test
What the above command does is invoking the Nix package manager to build all the machine configurations, then it transfers their corresponding package closures to the target machines and finally activates the NixOS configurations. The end result is a collection of machines running the new configuration, if all previous steps have succeeded.
If we adapt any of the network models, and run the deploy command again, the system is upgraded. In case of an upgrade, only the packages that have been changed are built and transferred, making this phase as efficient as possible.
We can also replace the physical network model shown earlier with the following model:
{
storage = {
deployment.targetEnv = "virtualbox";
deployment.virtualbox.memorySize = 1024;
};
postgresql = ...
webserver = ...
}
The above physical network configuration states that the storage machine is a VirtualBox Virtual Machine (VM) requiring 1024 MiB of RAM.
When we instantiate a new deployment with the above physical network model and deploy it:
$ nixops create ./network-logical.nix ./network-vbox.nix -d vbox $ nixops deploy -d vbox
NixOps does an extra step before doing the actual deployment of the system configurations -- it first instantiates the VMs by consulting VirtualBox and populates them with a basic NixOS disk image.
Similarly, we can also create a physical network model like this:
let
region = "us-east-1";
accessKeyId = "ABCD..."; # symbolic name looked up in ~/.ec2-keys
ec2 =
{ resources, ... }:
{ deployment.targetEnv = "ec2";
deployment.ec2.accessKeyId = accessKeyId;
deployment.ec2.region = region;
deployment.ec2.instanceType = "m1.medium";
deployment.ec2.keyPair = resources.ec2KeyPairs.my-key-pair;
deployment.ec2.securityGroups = [ "my-security-group" ];
};
in
{
storage = ec2;
postgresql = ec2;
webserver = ec2;
resources.ec2KeyPairs.my-key-pair = {
inherit region accessKeyId;
};
}
The above physical network configuration states that the storage machine is a virtual machine residing in the Amazon EC2 cloud.
Running the following commands:
$ nixops create ./network-logical.nix ./network-ec2.nix -d ec2 $ nixops deploy -d ec2
Automatically instantiates the virtual machines in EC2, populates them with basic NixOS AMI images and finally deploys the machines to run our desired Trac deployment.
(In order to make EC2 deployment work, you need to create the security group (e.g. my-security-group) through the Amazon EC2 console first and you must set the AWS_SECRET_ACCESS_KEY environment variable to contain the secret access key that you actually need to connect to the Amazon services).
Besides physical machines, VirtualBox, and Amazon EC2, NixOps also supports the Google Computing Engine (GCE) and Hetzner. Moreover, preliminary Azure support is also available in the development version of NixOps.
With NixOps you can also do multi-cloud deployment -- it is not required to deploy all VMs in the same IaaS environment. For example, you could also deploy the first machine to Amazon EC2, the second to Hetzner and the third to a physical machine.
In addition to deploying system configurations, NixOps can be used to perform many other kinds of system administration tasks that work on machine level.
Disnix
Readers who happen to know me a bit, may probably notice that many NixOps features are quite similar to things I did in the past -- while I was working for Delft University of Technology as a PhD student, I was investigating distributed software deployment techniques and developed a tool named: Disnix that also performs distributed deployment tasks using the Nix package manager as underlying technology.
I have received quite a few questions from people asking me things such as: "What is the difference between Disnix and NixOps?", "Is NixOps the successor of/a replacement for Disnix?", "Are Disnix and NixOps in competition with each other?"
The short answer is: while both tools perform distributed deployment tasks and use the Nix package manager as underlying (local) deployment technology, they are designed for different purposes and address different concerns. Furthermore, they can also be effectively used together to automate deployment processes for certain kinds of systems.
In the next chapters I will try to clarify the differences and explain how they can be used together.
Infrastructure and service deployment
NixOps does something that I call infrastructure deployment -- it manages configurations that work on machine level and deploys entire system configurations as a whole.
What Disnix does is service deployment -- Disnix is primarily designed for deploying service-oriented systems. What "service-oriented system" is exactly supposed to mean has always been an open debate, but a definition I have seen in the literature is "systems composed of platform-independent entities that can be loosely coupled and automatically discovered" etc.
Disnix expects a system to be decomposed into distributable units (called services in Disnix terminology) that can be built and deployed independently to machines in a network. These components can be web services (systems composed of web services typically qualify themselves as service-oriented systems), but this is not a strict requirement. Services in a Disnix-context can be any unit that can be deployed independently, such as web services, UNIX processes, web applications, and databases. Even entire NixOS configurations can be considered a "service" by Disnix, since they are also a unit of deployment, although they are quite big.
Whereas NixOps builds, transfers and activates entire Linux system configurations, Disnix builds, transfers and activates individual services on machines in a network and manages/controls them and their dependencies individually. Moreover, the target machines to which Disnix deploys are neither required to run NixOS nor Linux. They can run any operating system and system distribution capable of running the Nix package manager.
Being able to deploy services to heterogeneous networks of machines is useful for service-oriented systems. Although services might manifest themselves as platform independent entities (e.g. because of their interfaces), they still have an underlying implementation that might be bound to technology that only works on a certain operating system. Furthermore, you might also want to have the ability to experiment with the portability of certain services among operating systems, or effectively use a heterogeneous network of operating systems to use their unique selling points effectively for the appropriate services (e.g. a Linux, Windows, OpenBSD hybrid).
For example, although I have mainly used Disnix to deploy services to Linux machines, I also once did an experiment with deploying services implemented with .NET technology to Windows machines running Windows specific system services (e.g. IIS and SQL server), because our industry partner in our research project was interested in this.
To be able to do service deployment with Disnix one important requirement must be met -- Disnix expects preconfigured machines to be present running a so-called "Disnix service" providing remote access to deployment operations and some other system services. For example, to allow Disnix to deploy Java web applications, a predeployed Servlet container, such as Apache Tomcat, must already be present on the target machine. Also other container services, such as a DBMS, may be required.
Disnix does not automate the deployment of machine configurations (that include the Disnix service and containers) requiring people to deploy a network of machines by other means first and writing an infrastructure model that reflects the machine configurations accordingly.
Combining service and infrastructure deployment
To be able to deploy a service-oriented system into a network of machines using Disnix, we must first deploy a collection of machines running some required system services first. In other words: infrastructure deployment is a prerequisite for doing service deployment.
Currently, there are two Disnix extensions that can be used to integrate service deployment and infrastructure deployment:
- DisnixOS is an extension that complements Disnix with NixOS' deployment features to do infrastructure deployment. With this extension you can do tasks such as deploying a network of machines with NixOps first and then do service deployment inside the deployed network with Disnix.
Moreover, with DisnixOS you can also spawn a network of NixOS VMs using the NixOS test driver and run automated tests inside them.
A major difference from a user perspective between Disnix and DisnixOS is that the latter works with network models (i.e. networked NixOS configurations used by NixOps and the NixOS test driver) instead of infrastructure models and does the conversion between these models automatically.
A drawback of DisnixOS is that service deployment is effectively tied to NixOS, which is a Linux distribution. DisnixOS is not very helpful if a service-oriented system must be deployed in a heterogeneous network running multiple kinds of operating systems. - Dynamic Disnix. With this extension, each machine in the network is supposed to publish its configuration and a discovery service running on the coordinator machine generates an infrastructure model from the supplied settings. For each event in the network, e.g. a crashing machine, a newly added machine or a machine upgrade, a new infrastructure model is generated that can be used to trigger a redeployment.
The Dynamic Disnix approach is more powerful and not tied to NixOS specifically. Any infrastructure deployment approach (e.g. Norton Ghost for Windows machines) that includes the deployment of the Disnix service and container services can be used. Unfortunately, the Dynamic Disnix framework is still a rough prototype and needs to become more mature.
Is service deployment useful?
Some people have asked me: "Is service deployment really needed?", since it also possible to deploy services as part of a machine's configuration.
In my opinion it depends on the kinds of systems that you want to deploy and what problems you want to solve. For some kinds of distributed systems, Disnix is not really helpful. For example, if you want to deploy a cluster of DBMSes that are specifically tuned for specific underlying hardware, you cannot really make a decomposition into "distributable units" that can be deployed independently. Same thing with filesystem services, as shown in the Trac example -- doing an NFS mount is a deployment operation, but not a really an independent unit of deployment.
As a sidenote: That does not imply that you cannot do such things with Disnix. With Disnix you could still encapsulate an entire (or partial) machine specific configuration as a service and deploy that, or doing a network mount by deploying a script performing the mount, but that defeats its purpose.
At the same time, service-oriented systems can also be deployed on infrastructure level, but this sometimes leads to a number of inconveniences and issues. Let me illustrate that by giving an example:

The above picture reflects the architecture of one of the toy systems (Staff Tracker Java version) I have created for Disnix for demonstration purposes. The architecture consists of three layers:
- Each component in the upper layer is a MySQL database storing certain kinds of information.
- The middle layer encapsulates web services (implemented as Java web applications) responsible for retrieving and modifying data stored in the databases. An exception is the GeolocationService, which retrieves data by other means.
- The bottom layer contains a Java web application that is consulted by end-users.
Each component in the above architecture is a distributable service and each arrow denotes dependency relationships between them which manifest themselves as HTTP and TCP connections. Because components are distributable, we could, for example, deploy all of them to one single machine, but we can also run each of them on a separate machine.
If we want to deploy the example system on infrastructure level, we may end up composing a networked machine configuration that looks as follows:
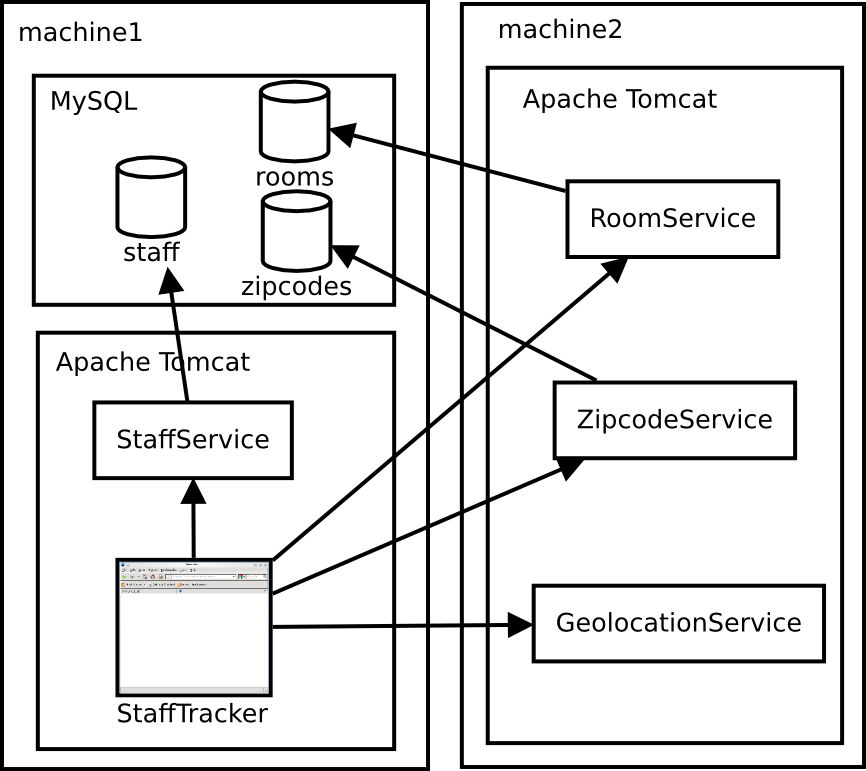
The above picture shows a deployment scenario in which the services are divided over two machines a network:
- The MySQL databases are hosted inside a MySQL DBMS running on the first machine.
- The web application front-end and one of the web services granting access to the databases are deployed inside the Apache Tomcat Servlet container running on the first machine.
- The remaining web services are deployed inside an Apache Tomcat container running on the second machine.
When we use NixOps to deploy the above machine configurations, then the entire machine configurations are deployed and activated as a whole, which have a number of implications. For example, the containers have indirectly become dependent on each other as can be seen in the picture below in which I have translated the dependencies from service level to container level:

In principle, Apache Tomcat does not depend on MySQL, so under normal circumstances, these containers can be activated in any order. However, because we host a Java web application that requires a database, suddenly the order in which these services are activated does matter. If we would activate them in the wrong order then the web service (and also indirectly the web application front-end) will not work. (In extreme cases: if a system has been poorly developed, it may even crash and need to be manually reactivated again!)
Moreover, there is another implication -- the web application front-end also depends on services that are deployed to the second machine, and two of these services require access to databases deployed to the first machine. On container level, you could clearly see that this situation leads to two machines having a cyclic dependency on each other. That means that you cannot solve activation problems by translating service-level dependencies to machine-level dependencies.
As a matter of fact: NixOps allows cyclic dependencies between machines and activates their configurations in arbitrary order and is thus incapable of dealing with temporarily or permanent inconsistency issues (because of broken dependencies) while deploying a system as shown in the example.
Another practical issue with deploying such a system on infrastructure level is that it is tedious to do redeployment, for example when a requirement changes. You need to adapt machine configurations as a whole -- you cannot easily specify a different distribution scenario for services to machines.
As a final note, in some organisations (including a company that I have worked for in the past) it is common practice that infrastructure and service deployment are separated. For example, one department is responsible for providing machines and system services and another department (typically a development group) responsible for building the services and deploying them to the provided machines.
Conclusion
In this blog post, I have described NixOps and elaborated on the differences between NixOps and Disnix -- the former tool does infrastructure deployment, while the latter does service deployment. Infrastructure deployment is a prerequisite of doing service deployment and both tools can actually be combined to automate both concerns.
Service deployment is particularly useful for distributed systems that can be decomposed into "distributable units" (such as service-oriented systems), but not all kinds of distributed systems.
Moreover, NixOps is a tool that has been specifically designed to deploy NixOS configurations, while Disnix can deploy services to machines running any operating system capable of running the Nix package manager.
Finally, I have been trying to answer three questions, which I mentioned somewhere in the middle of this blog post. There is another question I have intentionally avoided that obviously needs an answer as well! I will elaborate more on this in the next blog post.
References
More information about Disnix, service and infrastructure deployment, and in particular: integrating deployment concerns can be found in my PhD thesis.
Interestingly enough, during my PhD thesis defence there was also a question about the difference between service and infrastructure deployment. This blog post is a more elaborate version of the answer I gave earlier. :-)
Hi,
ReplyDeleteThank you for the great post & excellent advice. I’ve been reading this blog; it’s very informative for anyone
Hacker News thread: https://news.ycombinator.com/item?id=9281300
ReplyDelete