The definition of a service in a Disnix context is not very strict. Basically, a service can take almost any form, such as a web service, web application, UNIX processes and even entire NixOS configurations.
Apart from the fact that we can deploy various kinds of services, they have another important characteristic from a deployment perspective. By default, services are target-agnostic, which means that they always have the same form regardless to what machine they are deployed in the network. In most cases this is considered a good thing.
However, there are also situations in which we want to deploy services that are built and configured specifically for a target machine. In this blog post, I will elaborate on this problem and describe how target-specific services can be deployed with Disnix.
Target-agnostic service deployment
Why are services target-agnostic by default in Disnix?
This property actually stems from the way "ordinary packages" are built with the Nix package manager which is used as a basis for Disnix.
As explained earlier, Nix package builds are influenced by its declared inputs only, such as the source code, build scripts and other kinds of dependencies, e.g. a compiler and libraries. Nix has means to ensure that undeclared dependencies cannot influence a build and that dependencies never collide with each other.
As a result, builds are reliable and reproducible. For example, it does not matter where the build of a package is performed. If the inputs are the same, then the corresponding outcome will be the same as well. (As a sidenote: there are some caveats, but in general there are no observable side-effects). Also, it provides better guarantees that, for example, if I have build and tested a program on my machine that it will work on a different machine as well.
Moreover, since it does not matter where a package has been built, we can, for example, also download a package built from identical inputs from a remote location, instead of building it ourselves improving the efficiency of deployment processes.
In Disnix, Nix's concept of building packages has been extended to services in a distributed setting. The major difference between a package and a serivce is that services take an additional class of dependencies into account. Besides the intra-dependencies that Nix manages, services may also have inter-dependencies on services that may be deployed to remote machines in a network. Disnix can be used to configure services in such a way that a service knows how to reach them and that the system is activated and deactivated in the right order.
As a consequence, it does not take a machine's properties into account when deploying it to a target machine in the network unless a machine's properties are explicitly provided as dependencies of a service.
In many cases, this is a good thing. For example, the following image shows a particular deployment scenario of the ridiculous StaffTracker example (described in some of my research publications and earlier blog posts):
The above image describes a deployment scenario in which we have deployed services (denoted by the ovals) to two machines in a network (denoted by the grey boxes). The arrows denote inter-dependency relationships.
One of the things we could do is changing the location of the StaffTracker web application front-end service, by changing the following line in the distribution model:
StaffTracker = [ infrastructure.test2 ];
to:
StaffTracker = [ infrastructure.test1 ];
Redeploying the system yields the following deployment architecture:
Performing the redeployment procedure is actually quite efficient. Since the intra-dependencies and inter-dependencies of the StaffTracker service have not changed, we do not have to rebuild and reconfigure the StaffTracker service. We can simply take the existing build result from the coordinator machine (that has been previously distributed to machine test1) and distribute it to test2.
Also, because the build result is the same, we have better guarantees that if the service worked on machine test1, it should work on machine test2 as well.
(As a sidenote: there is actually a situation in which a service will get rebuilt when moving it from one machine to another while its intra-dependencies and inter-dependencies have not changed.
Disnix also supports heterogeneous service deployment meaning that we can run target machines having different CPU architectures and operating systems. For example, if test2 were a Linux machine and test1 a Mac OS X machine, Disnix attempts to rebuild it for the new platform.
However, if all machines have the CPU architecture and operating system this will not happen).
Deploying target-specific services
Target-agnostic services are generally considered good because they improve reproducibility and efficiency when moving a service from machine to another. However, in some situations you may need to configure a service for a target machine specifically.
An example of a deployment scenario in which we need to deploy target-specific services, is when we want to deploy a collection of Node.js web applications and an nginx reverse proxy in which each web application should be reached by its own unique DNS domain name (e.g. http://webapp1.local, http://webapp2.local etc.).
We could model the nginx reverse proxy and each web application as (target-agnostic) distributable services, and deploy them in a network with Disnix as follows:
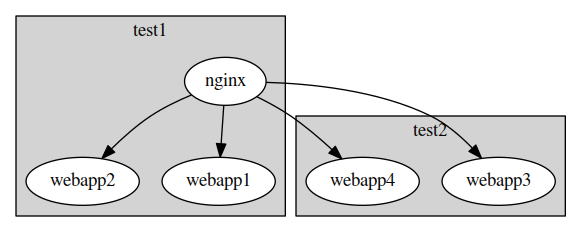
We can declare the web applications to be inter-dependencies of the nginx service and generate its configuration accordingly.
Although this approach works, the downside is that in the above deployment architecture, the test1 machine has to handle all the network traffic including the requests that should be propagated to the web applications deployed to test2 making the system not very scalable, because only one machine is responsible for handling all the network load.
We can also deploy two redundant instances of the nginx service by specifying the following attribute in the distribution model:
nginx = [ infrastructure.test1 infrastructure.test2 ];
The above modification yields the following deployment architecture:

The above deployment architecture is more scalable -- now requests meant for any of the web applications deployed to machine test1 can be handled by the nginx server deployed to test1 and the nginx server deployed to test2 can handle all the requests meant for the web applications deployed to test2.
Unfortunately, there is also an undesired side effect. As all the nginx services have the same form regardless to which machines they have been deployed, they have inter-dependencies on all web applications in the entire network including the ones that are not running on the same machine.
This property makes upgrading the system very inefficient. For example, if we update the webapp3 service (deployed to machine test2), the nginx configurations on all the other machines must be updated as well causing all nginx services on all machines to be upgraded, because they also have an inter-dependency on the upgraded web application.
In a 2 machine scenario with 4 web applications, this inefficiency may still be acceptable, but in a big environment with tens of web applications and tens of machines, we most likely suffer from many (hundreds of) unnecessary redeployment activities bringing the system down for a unnecessary long time.
A more efficient deployment architecture would be the following:

We deploy two target-specific nginx services that only have inter-dependencies on the web applications deployed to the same machine. In this scenario, upgrading webapp3 does not affect the configurations of any of the services deployed to the test1 machine.
How to specify these target-specific nginx services?
A dumb way to do it is to define a service for each target in the Disnix services model:
{pkgs, system, distribution}:
let
customPkgs = ...
in
rec {
...
nginx-wrapper-test1 = rec {
name = "nginx-wrapper-test1";
pkg = customPkgs.nginx-wrapper;
dependsOn = {
inherit webapp1 webapp2;
};
type = "wrapper";
};
nginx-wrapper-test2 = rec {
name = "nginx-wrapper-test2";
pkg = customPkgs.nginx-wrapper;
dependsOn = {
inherit webapp3 webapp4;
};
type = "wrapper";
};
}
And then distributing them to the appropriate target machines in the Disnix distribution model:
{infrastructure}:
{
...
nginx-wrapper-test1 = [ infrastructure.test1 ];
nginx-wrapper-test2 = [ infrastructure.test2 ];
}
Manually specifying target-specific services is quite tedious and labourious especially if you have tens of services and tens of machines. We have to specify machines x components services resulting in hundreds of target-specific service configurations.
Furthermore, there is a bit of repetition. Both the distribution model and the service models reflect mappings from services to target machines.
A better approach would be to generate target-specific services. An example of such an approach is to specify the mappings of these services in the distribution model first:
{infrastructure}:
let
inherit (builtins) listToAttrs attrNames getAttr;
in
{
webapp1 = [ infrastructure.test1 ];
webapp2 = [ infrastructure.test1 ];
webapp3 = [ infrastructure.test2 ];
webapp4 = [ infrastructure.test2 ];
} //
# To each target, distribute a reverse proxy
listToAttrs (map (targetName: {
name = "nginx-wrapper-${targetName}";
value = [ (getAttr targetName infrastructure) ];
}) (attrNames infrastructure))
In the above distribution model, we statically map all the target-agnostic web application services, and for each target machine in the infrastructure model we generate a mapping of the target-specific nginx service to its target machine.
We can generate the target-specific nginx service configurations in the services model as follows:
{system, pkgs, distribution, invDistribution}:
let
customPkgs = import ../top-level/all-packages.nix {
inherit pkgs system;
};
in
{
webapp1 = ...
webapp2 = ...
webapp3 = ...
webapp4 = ...
} //
# Generate nginx proxy per target host
builtins.listToAttrs (map (targetName:
let
serviceName = "nginx-wrapper-${targetName}";
servicesToTarget = (builtins.getAttr targetName invDistribution).services;
in
{ name = serviceName;
value = {
name = serviceName;
pkg = customPkgs.nginx-wrapper;
# The reverse proxy depends on all services distributed to the same
# machine, except itself (of course)
dependsOn = builtins.removeAttrs servicesToTarget [ serviceName ];
type = "wrapper";
};
}
) (builtins.attrNames invDistribution))
To generate the nginx services, we iterate over a so-called inverse distribution model mapping targets to services that has been computed from the distribution model (mapping services to one or more machines in the network).
The inverse distribution model is basically just the infrastructure model in which each target attribute set has been augmented with a services attribute containing the properties of the services that have been deployed to it. The services attribute refers to an attribute set in which each key is the name of the service and each value the service configuration properties defined in the services model:
{
test1 = {
services = {
nginx-wrapper-test1 = ...
webapp1 = ...
webapp2 = ...
};
hostname = "test1";
};
test2 = {
services = {
nginx-wrapper-test2 = ...
webapp3 = ...
webapp4 = ...
};
hostname = "test2";
};
}
For example, if we refer to invDistribution.test1.services we get all the configurations of the services that are deployed to machine test1. If we remove the reference to the nginx reverse proxy, we can pass this entire attribute set as inter-dependencies to configure the reverse proxy on machine test1. (The reason why we remove the reverse proxy as a dependency is because it is meaningless to let it refer to itself. Furthermore, this would also cause infinite recursion).
With this approach we can also easily scale up the environment. By simply adding more machines in the infrastructure model and additional web application service mappings in the distribution model, the service configurations in the service model get adjusted automatically not requiring us to think about specifying inter-dependencies at all.
Conclusion
To make target-specific service deployment possible, you need to explicitly define service configurations for specific target machines in the Disnix services model and distribute them to the right targets.
Unfortunately, manually specifying target-specific services is quite tedious, inefficient and laborious, in particular in big environments. A better solution would be to generate the configurations of target-specific services.
To make generation more convenient, you may have to refer to the infrastructure model and you need to know which services are deployed to each target.
I have integrated the inverse distribution generation feature into the latest development version of Disnix and it will become part of the next Disnix release.
Moreover, I have developed yet another example package, called the Disnix virtual hosts example, to demonstrate how it can be used.