In my last blog post,
I have shown how I have been using Linux on my Amiga 4000. Running Linux on an Amiga has always been a fascinating use case to me -- I have developed strong interests in both areas from a very young age.
Shortly after buying my second-hand Amiga 4000 in 2022, I discovered
an interesting Reddit article stating that NetBSD (another UNIX-like operating system) supports the Amiga. The title of this article was IMO somewhat confusing, because it suggests that support for the Amiga was recently added, but that statement is false --
NetBSD already
supports the Amiga since its 1.0 release (done in 1994). Amiga support was heavily improved in 2022.
NetBSD is an interesting operating system -- it is the first BSD derivative that was forked from
386BSD by a group of developers in 1992 that were dissatisfied with its development process.
FreeBSD is a fork started by another group of developers in the same year.
OpenBSD was forked from NetBSD in 1995 and
DragonFly BSD from FreeBSD in 2003 due to disagreements.
Each of these BSD derivatives have different goals and standards. NetBSD's focus is portability and simplicity. Its slogan is "of course it runs NetBSD" and facilitates a design and infrastructure that makes porting to new platforms relatively easy. As a result, it has been ported to many kinds of CPUs and hardware architectures, including the PC and the Amiga.
The other BSD derivatives have different goals -- OpenBSD is focused on security and correctness and FreeBSD's purpose is to be a more balanced/general purpose BSD derivative. DragonFly BSD's focus is threading and symmetric multiprocessing.
Another interesting story about NetBSD and the Amiga is its porting process. In order to port NetBSD to the Amiga, the build tool chain had to be ported to AmigaOS first. The result of this porting process is a library project called:
ixemul.library providing a UNIX system call interface on top of AmigaOS.
The
ixemul.library is the main ingredient of the
Geek Gadgets distribution that offers a large collection of UNIX utilities that can be used on top of AmigaOS. Some time ago,
I have used the Nix package manager to automate package builds with these tools to port
my IFF file formats project from Linux to AmigaOS and creating a viewer program for AmigaOS.
Although NetBSD is an interesting operating system, I have never used any of the BSD derivatives as much as I have used Linux. For example, I have never used any of them as a desktop operating system.
I have the most experience with FreeBSD -- I have used it for web servers, as a porting target for the
Nix package manager so that we could add another build target to our university's build farm (that uses
Hydra: the Nix-based continuous integration system), and as a porting target for my
my experimental Nix process management framework.
My experience with OpenBSD and NetBSD is more limited -- the only notable use case I have with them is to use them as porting targets for the Nix package manager, similar to FreeBSD. Apart from a few simple experiments, I never did anything meaningful with DragonFly BSD.
Because of the impact of the article and my past experiences with NetBSD, trying it out on my Amiga 4000 was high on my TODO list. It was a nice experience -- beyond installing NetBSD it was also the first time for me to use it as an operating system to "do work with", rather than a development target.
In this blog post, I will report about my experiences.
Getting started with NetBSD for the Amiga
In my previous blog post (covering Linux on Amiga), I explained that it was a bit of a challenge to start, because much of the information that I need is outdated and scattered.
With NetBSD, the starting process was much easier for me --
NetBSD for the Amiga has IMO a very well written web page from which I can easily obtain the installation CD-ROM ISO file and Amiga-specific installation instructions.
Moreover, contrary to Debian, I can use the latest version of NetBSD (version 10.1 at the time writing this blog post) on my Amiga 4000. With Debian, I was not able to use any version newer than 3.1.
(To be precise: the m68k port was discontinued after Debian 3.1, but re-introduced in Debian 9.0. Unfortunately, 9.0 and newer versions did not work for me. The latest version of Debian is 12.9 at the time writing this blog post).
Installing NetBSD on the Amiga 4000
The
installation procedure does not appear to be very user friendly, but is IMO not too difficult if you already have some experience with AmigaOS and a UNIX-like operating system.
To produce a working NetBSD installation on an Amiga I followed their documentation. From a high-level point of view it consists of the following steps:
- Downloading an ISO file and burning it to a writable CD-ROM.
- Booting up my Amiga 4000 and creating a partition layout suitable for using NetBSD. Similar to Linux, NetBSD can be installed next to an existing AmigaOS installation on a separate partition. There are a couple things that need to be kept in mind:
- Partitioning must be done by using native AmigaOS tools, such as HDToolBox. NetBSD does not provide its own partitioning tool.
- We must use HDToolBox to manually specify the correct partition identifiers for the NetBSD swap and root partition. Manual specification is a bit cumbersome, but necessary -- HDToolBox does not recognize these partition types by itself
- We must make the swap and root partitions bootable. Furthermore, we need to allow custom boot blocks for these partitions. More information about this later.
- The swap and root partitions must be under the 4 GiB limit. This limit turns out to be a hard limit for my machine as well -- even though my AmigaOS 3.9 homebrew kickstart ROM has a SCSI driver that is not restricted by the 4 GiB limitation, the boot menu does not seem to recognize bootable partitions above this limit.
To address the 4 GiB requirement, I ended up creating a 1 GiB AmigaOS partition containing the Amiga Workbench, followed by a 128 MiB NetBSD swap partition, followed by a 2 GiB NetBSD root partition. The remaining disk space is used for partitions used by AmigaOS.
- Transferring the miniroot filesystem image from the CD-ROM to the swap partition. The miniroot filesystem contains a minimal NetBSD installation capable of performing the actual installation of the NetBSD distribution.
- Booting from the swap partition to set the NetBSD installation procedure in motion. The installer is text-based and asks a number of questions. The package installation process takes several hours on my Amiga to complete.
- Rebooting the machine from the root partition and completing the NetBSD installation.
The NetBSD boot process
Similar to Linux, NetBSD has an interesting boot process -- using these operating systems require the presence of a running kernel. A kernel is not magically there, but needs to be loaded from an external location first. A
boot loader is a program that is responsible for facilitating this process.
In my previous blog post, I have explained that are variety of ways to do boot loading. Most importantly, it is possible to load a kernel as quickly as possible after powerup using as few facilities from the ROM or the native operating system. This is a process that I will call
cold booting.
In addition, it is possible to first boot into an existing operating system and load a kernel image while the existing operating system is running. Once the kernel is loaded it can take control of the system. This is a process that I called
warm booting.
On the Amiga, it is a common practice to warm boot Linux (contrary to Linux on PCs, where cold booting is the normal practice). With NetBSD on Amiga it is actually the opposite -- cold booting is the preferred practice.
As I have already explained in the previous section, we must make the swap and root partitions bootable in HDToolBox. Furthermore, we must allow these partitions to use custom bootblocks.
When powering up my Amiga, I can hold both mouse buttons to enter the boot menu. In the boot menu, I can select the partition that I want to boot from (by default, it traverses the list of bootable drives/partitions top down and takes the first workable option):
In the above screenshot, our NetBSD partitions are also visible as possible boot partitions.
When I select:
netbsd-root I can boot from my NetBSD root partition that contains a custom boot block providing a boot loader. The bootloader can be used to load a NetBSD kernel with my desired command-line parameters:
Although cold booting is the preferred practice according to the documentation, it is also possible to warm boot a NetBSD kernel. The
loadbsd command can be used for this -- it is an Amiga tool that can load a kernel image from an Amiga partition with a number of kernel parameters. Once the kernel has been loaded, it can take control of the system.
There is yet another way to start NetBSD -- there is also a command-line tool called
runbootblock. This tool can be used to automatically execute the code stored in a bootblock of a partition from a running AmigaOS session.
I guess this approach falls in between warm and cold booting -- it is warm booting a kernel from a running operating system using the facilities of a cold booting process. I guess this method can be called
lukewarm booting.
Although I am fine with using the Amiga Kickstart's boot menu, I also find it convenient to boot into NetBSD when I am already in the Amiga Workbench. To do that, I have created a desktop icon called
StartNetBSD to lukewarm boot into NetBSD:
The icon in the bottom right corner above executes the following script:
runbootblock -dscsi.device -u0 -pnetbsd-root
The above command specifies that we want to run the bootblock of the partition
netbsd-root that resides on the first drive unit. We use the
scsi.device driver to get access to the partition.
Lukewarm booting seems to work fine if I use the Amiga's chipset for the framebuffer. Unfortunately, when using my Cybervision 64/3D RTG card, the screen looks messed up. I discovered that AmigaOS' initialization of the VGA display is the culprit -- as a result, if I want to use NetBSD in combination with my RTG card, I always need to do a full cold boot.
Post installation steps
After completing the NetBSD installation, there are number of additional configuration steps that I had to perform to get all of my use cases supported. I took heavy inspiration from
this NetBSD 9.2 Amiga post installation guide.
Switching off unneeded services
The first thing I noticed after first startup is that my NetBSD installation boots quite slowly. After logging in, it still behaves slowly.
By running
ps I figured out that there is a background process:
makemandb that consumes quite a bit of my CPU's time. Moreover, I noticed that
postfix takes quite a bit of time to start on boot up.
Because I do not need these services, I have disabled them at startup by adding the following lines to
/etc/rc.conf:
makemandb=NO
postfix=NO
Configuring user accounts
By default, there is only one user account -- the root user, that has full privileges. Moreover, the root user has no password set.
We can configure the root password by running the following command:
$ passwd
We can configure an unprivileged user account and set a password as follows:
$ useradd -m -G wheel sander
$ passwd sander
Enabling wscons
In the default installation, the command-line experience is somewhat primitive -- I only have a gray background with black colored text and a single terminal window.
To enhance the NetBSD command-line experience, I can enable
wscons: NetBSD's platform-independent workstation console driver -- it handles complete abstraction of keyboards and mice and it can multiplex terminals.
To enable wscons, we first need to deploy a kernel that supports it -- the default kernel does not have that functionality built in.
A wscons-enabled kernel can be found on the NetBSD CD-ROM. I can replace the default kernel by logging into my NetBSD installation and running the following commands:
$ mount /dev/cd0a /cdrom
$ cd /
$ cp /cdrom/amiga/binary/kernel/netbsd-WSCONS.gz /
$ gunzip netbsd-WSCONS.gz
$ mv netbsd netbsd-ORIG
$ mv netbsd-WSCONS netbsd
In the above code fragment, I copy the wscons-enabled kernel from the NetBSD CD-ROM to the root directory, uncompress it, make a backup of the old kernel and finally replace the default kernel with the new kernel.
We must also enable the wscons service on startup. This can be done by adding the following line to
/etc/rc.conf:
wscons=YES
To use multiple terminals, we must open
/etc/ttys in a text editor and enable the
ttyE1,
ttyE2 and
ttyE3 consoles by switching their 'off' flags to 'on':
Finally, we must reboot the system so that we can use the wscons-enabled kernel.
Configuring frame buffer video modes
Another thing I was curious about is how I can configure the output device and resolutions for the framebuffer. For example, when I boot up the kernel, NetBSD automatically uses my Cybervision 64/3D RTG card's display using a 640x480 resolution in 8-bit color mode.
Although I am happy to use my RTG card, I also want to have the ability to use Amiga's AGA chipset for graphics. Moreover, I want to have ability to switch to different graphics modes.
On Linux this can be done by passing the appropriate
video parameter to the kernel. On NetBSD, this turns out to be a very tricky configuration aspect.
According to the
boot manual page (that describes the NetBSD kernel's boot parameters), there is only one display-related kernel parameter:
-A. The documentation says that this parameter enables AGA display mode, but it actually does two things -- it indeed enables AGA mode so that the display uses 256 colors, but it also configures the display to use a "double NTSC" screen mode (640x400, non-interlaced).
Without the
-A parameter, the NetBSD kernel is instructed to use 8 colors and an NTSC high resolution interlaced screen mode (640x400). Although my Amiga has an AGA chipset, my LED TV does not seem to accept double NTSC or double PAL screen modes.
In addition to very limited native Amiga chipset configuration abilities, I did not see any kernel parameters that allow me to select my preferred framebuffer device. After some searching, I learned that
it is not possible to provide more screen mode settings.
While studying the
NetBSD post installation notes GitHub gist, I learned that I am not the only person running into problems with the display. In the gist, the author describes how he adjusted the display settings for the AGA display mode to match the settings of a VGA output by copying the settings from the Linux amifb driver and cross compiling the NetBSD kernel for the Amiga.
I ended up cross compiling a kernel myself as well by following the same instructions. To do the cross compilation, I have downloaded a NetBSD 10.1 distribution ISO file for x64 machines and installed it in a
VirtualBox virtual machine on my PC.
In this VirtualBox virtual machine, I have downloaded the NetBSD 10.1 source code by running:
$ cvs -d anoncvs@anoncvs.NetBSD.org:/cvsroot checkout -P -r netbsd-10-1-RELEASE src
I can set up the cross compilation toolchain by running:
$ cd src
$ ./build.sh -m amiga tools
The above command automatically downloads the required dependencies (e.g. the source tarballs for the cross compiler, cross linker etc.) and compiles them.
My first goal was to see if I can make the required adjustments to force the kernel to use the Amiga chips to display the framebuffer. I ended up editing two files and disabling a number of options.
The first file that I have changed is the following:
sys/arch/amiga/conf/GENERIC. I have commented out the following properties:
#options RETINACONSOLE # enable code to allow retina to be console
#options CV64CONSOLE # CyberVision console
#options TSENGCONSOLE # Tseng console
#options CV3DCONSOLE # CyberVision 64/3D console
#options GRF_AGA_VGA # AGA VGAONLY timing
#options GRF_SUPER72 # AGA Super-72
#grfrt0 at zbus0 # retina II
#grfrh0 at zbus0 # retina III
#grfcv0 at zbus0 # CyberVision 64
#grfet* at zbus0 # Tseng (oMniBus, Domino, Merlin)
#grfcv3d0 at zbus0 # CyberVision 64/3D
#grf1 at grfrt0
#grf2 at grfrh0
#grf5 at grfcv0
#grf6 at grfet?
#grf7 at grfcv3d0
#ite1 at grf1 # terminal emulators for grfs
#ite2 at grf2 # terminal emulators for grfs
#ite5 at grf5 # terminal emulators for grfs
#ite6 at grf6 # terminal emulators for grfs
#ite7 at grf7 # terminal emulators for grfs
The most important property to comment out is the
CV3DCONSOLE. Disabling the Cybervision 64/3D console ensures that my Cybervision 64/3D card never gets detected. As a result, NetBSD is forced to use the native Amiga chipset.
As a side effect of disabling the Cybervision 64/3D console option, I must also disable
the corresponding color graphics driver (
grfcv3d0), framebuffer device (
grf7) and
terminal emulator device (
ite7).
In addition to Cybergraphics 64/3D, I have been disabling a number of additional features that I do not need. For example, I do not need any support for unorthodox resolutions (VGA, Super72). I can also disable support for additional RTG cards because I do not have them.
As a side effect of disabling their consoles, I must also disable their corresponding color graphics drivers, framebuffer devices and terminal emulation devices.
Another file that I need to modify is the wscons configuration (
sys/arch/amiga/conf/WSCONS):
#no grfrt0 at zbus0
#no grfrh0 at zbus0
#no grf1 at grfrt0
#no grf2 at grfrh0
#no ite1 at grf1
#no ite2 at grf2
#no ite5 at grf5
#no ite6 at grf6
#no ite7 at grf7
In the above file, I also need to disable the color graphics, framebuffer and terminal emulation devices that I have commented out in the previous configuration file.
After configuring the kernel, I can compile it with the following command-line instruction:
$ ./build.sh -m amiga kernel=WSCONS
The resulting kernel image can be found in:
src/sys/arch/amiga/compile/obj/WSCONS/netbsd. I have copied the resulting kernel image to my NetBSD root partition and named it:
netbsd-NORTG.
If I want to use a NetBSD session using my Amiga's chips (with a 8-color interlaced high resolution screen mode), then I can provide the following command to the bootloader:
netbsd-NORTG -Sn2
Resulting in the following NetBSD session:
As can be seen in the picture above, I have successfully instructed the bootloader to load my custom NORTG NetBSD kernel forcing the operating system to use the Amiga display driver.
After compiling my custom NORTG kernel, I have also been experimenting with the kernel source code to see if I can somehow avoid using the incompatible "double NTSC" screen mode. Unfortunately, I discovered that screen modes are hardcoded in the kernel (to be precise, I found them in this file:
src/sys/arch/amiga/dev/grfabs_cc.c).
After trying out a few display settings (including the VGA monitor settings described in the GitHub gist) I discovered that if I cut the amount of scan lines in half for the AGA screen mode, I can get an acceptable display in AGA mode (at least in the console).
Unfortunately, despite this achievement I realized that my customized AGA mode is useless -- if I want to use the X Window System, the display server does not seem to know how to use my hacked screen mode. As a result, it fails to start.
I eventually gave up investigating this problem and decided to simply use the non-AGA graphics mode.
Using the X Window System
A nice property of the X Window System on NetBSD/Amiga is that it integrates with wscons. As a result, it has a very minimal configuration process.
Something that appears to be missing is the presence of a pseudo terminal device file. Without it, xterm refuses to start. I can create this missing device file by running the following commands:
$ cd /dev
$ ./MAKEDEV pty0
Another nice property is that, in contrast to the X Window System for Debian Linux/Amiga, the NetBSD version also supports the Amiga chipset for displaying graphics.
When using a NORTG kernel console session, I can simply run:
startx and after a while, it shows me this:
The picture above shows a CTWM session with some running applications. The only two downsides of using the X Window System on the Amiga is that it takes quite a bit of time to boot up and I can only use monochrome graphics.
To have a color display, I need to enable AGA mode. As already explained, I cannot use the AGA screen mode because my display cannot handle double PAL or double NTSC screen modes.
Adjusting screen modes
As far as I could see, it is not possible to change screen modes at runtime while using the Amiga chipset.
With my Cybervision 64/3D RTG card it is actually possible to change screen modes at runtime.
To do that, I need to load a screen mode definition file. I made an addition to the
/etc/rc.local script to load such a definition file at boot time:
$ grfconfig /dev/grf7 /etc/gfxmodes
In the above command-line instruction, the
/dev/grf7 parameter corresponds to the Cybervision 64/3D framebuffer device (this device file can be determined by looking at the output of the
dmesg command) and
/etc/gfxmodes to a screen mode definition file.
Writing a
screen mode definition file is a bit cumbersome. Fortunately, from my previous experiments with the
Picasso96Mode Amiga preferences tool, I discovered that this tool also has a feature to generate NetBSD 1.2 and 1.3 compatible mode definitions. I learned that NetBSD 10.1 still uses the same format as NetBSD 1.3
To automatically save these mode settings to a file, I need to open a CLI in my Amiga Workbench and run the following command:
SYS:Prefs/Picasso96Mode >T:gfxmodes
The above command opens the
Picasso96Mode preferences program and redirects the standard output to
T:gfxmodes.
In the Picasso96 GUI, I must select all relevant screen modes and select the menu option: Mode -> Print Mode to export the screen mode (as shown in the picture above).
To get a reasonable coverage, I start with the lowest resolution and color mode (8-bit). Then I move to higher color modes, then higher resolutions etc. until all the screen modes that I need are covered.
After exporting all relevant screen modes, I need to open the
T:gfxmodes file in a text editor and remove all comments and NetBSD 1.2 entries. What remains is a file that has the following structure:
x 26249996 640 480 8 640 688 768 792 479 489 492 518 default
x 43977267 800 600 8 800 832 876 976 599 610 620 638 +hsync +vsync
x 67685941 1024 768 8 1024 1072 1184 1296 767 772 777 798 default
In the above file, each line represents a screen mode. The first defines a 640x480 resolution screen, the second an 800x600 resolution screen and the third a 1024x768 resolution screen. All three screen modes use an 8-bit color palette.
We need to slightly adjust this file to allow it to work with NetBSD -- the first column (that contains an 'x' character) represents a mode number. We need to give it a unique numeric value or a 'c' to define the screen mode of the console.
If I want my console to use a 640x480 screen mode, and keep the remaining screen modes as an option, I can change the above mode definition file into:
c 26249996 640 480 8 640 688 768 792 479 489 492 518 default
1 26249996 640 480 8 640 688 768 792 479 489 492 518 default
2 43977267 800 600 8 800 832 876 976 599 610 620 638 +hsync +vsync
3 67685941 1024 768 8 1024 1072 1184 1296 767 772 777 798 default
In the above file, I have replaced the 'x' characters by unique numeric values and I have duplicated the 640x480 mode to be the console screen mode.
By copying the above file to
/etc/gfxlogin on my NetBSD root partition, I can switch between screen modes if desired.
I learned that to use the X Window System in combination with my Cybervision 64/3D card, I also require a modes defintion file. By default, the X Window System uses the first screen mode (screen mode:
1). When I start the X server, I eventually get to see the following display:
Installing custom packages
Contrary to Linux, which is a kernel that needs to be combined with other software packages (for example, from the GNU project) to become a functional distribution, NetBSD is a complete system. However, I do need some extra software to make my life more convenient, such as
the Midnight Commander.
NetBSD includes a package manager:
pkgsrc and
a package repository with a variety of software packages. Automatically downloading and installing prebuilt binaries and their dependencies can be conveniently done with a front-end for pkgsrc:
pkgin.
Unfortunately, as I have already explained in my previous blog post, my Amiga 4000 machine does not have a network card. The only means I have to link it up to the Internet is a null-modem cable which is too slow for downloading packages.
Fortunately, the web-based interface of pkgsrc is easy enough to manually download the packages I want and their dependencies. For example, to obtain Midnight Commander, I can open the following page:
https://ftp.netbsd.org/pub/pkgsrc/current/pkgsrc/sysutils/mc46/index.html, download the m68k tarball, follow the runtime dependencies, download their tarballs, and then the transitive dependencies etc.
To install the downloaded packages on NetBSD, I just copy them to a directory on my NetBSD drive. Then I can install them with the
pkg_add command:
$ pkg_add /root/packages/mc-4.6.1nb28.tgz
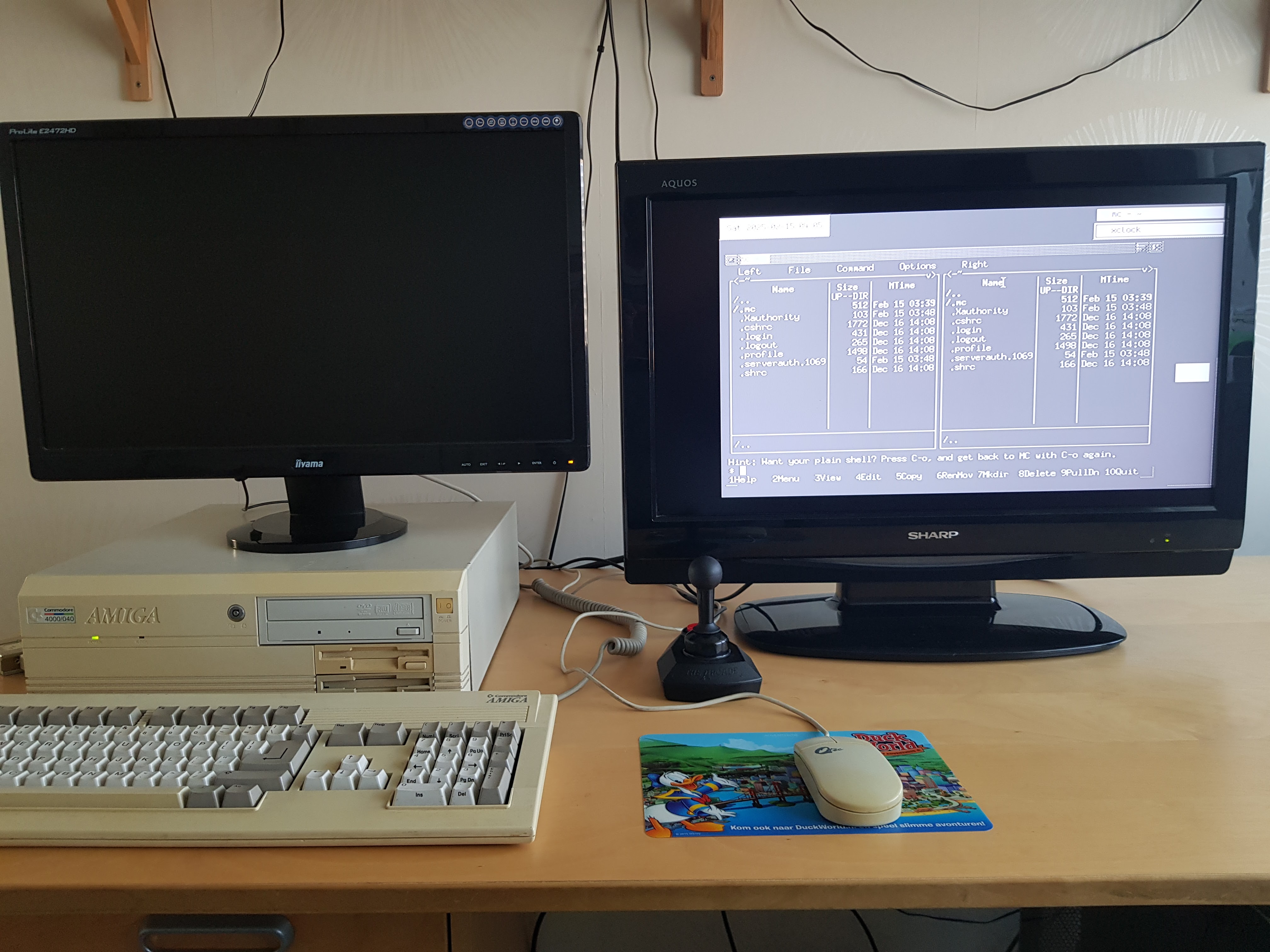
The result is that I can use Midnight Commander on NetBSD on my Amiga:
Setting up a terminal connection between the Amiga and PC with a null-modem cable
In my previous blog post about running Linux on my Amiga, I have been using a null-modem cable to link the Amiga to my PC. With NetBSD, I can do the same thing. For example, on my Linux PC I can start a terminal session over the serial port:
$ agetty --flow-control ttyUSB0 19200
and use Minicom on my NetBSD/Amiga installation to remotely connect to it.
I can also do the opposite -- I can enable a serial console on NetBSD by editing
/etc/ttys and enabling a terminal for the
/dev/tty00 device:
tty00 "/usr/libexec/getty std.9600" unknown on secure
Then I can use
minicom on my Linux PC to remotely connect to my Amiga:
$ minicom -b 9600 -D /dev/ttyUSB0
The result can be seen in the following picture:
Connecting to the Internet
Similar to my Linux setup, I can also connect my NetBSD/Amiga installation to the Internet. The recipe is exactly the same. I took inspiration from the
Linux PPP HOWTO for this.
First, I need to set up a link end point on my Amiga 4000, with the following command:
$ pppd -detach crtscts lock noauth defaultroute 192.168.1.2:192.168.1.1 /dev/tty00 19200
Then I can configure my desktop PC (which has a connection to the Internet by using an ethernet card):
$ pppd -detach crtscts lock noauth proxyarp 192.168.1.1:192.168.1.2 /dev/ttyUSB0 19200
Then I should be able to ping my desktop PC from the Amiga by running:
$ ping 192.168.1.1
With some additional steps, I can connect my Amiga 4000 to the Internet by using my desktop PC as a gateway.
First, I need to enable IP forwarding on my desktop PC:
echo 1 > /proc/sys/net/ipv4/ip_forward
Then, on my desktop PC,
I can enable network address translation (NAT) as follows:
INTERNAL_INTERFACE_ID="ppp0"
EXTERNAL_INTERFACE_ID="enp6s0"
iptables -t nat -A POSTROUTING -o $EXTERNAL_INTERFACE_ID -j MASQUERADE
iptables -A FORWARD -i $EXTERNAL_INTERFACE_ID -o $INTERNAL_INTERFACE_ID -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -i $INTERNAL_INTERFACE_ID -o $EXTERNAL_INTERFACE_ID -j ACCEPT
In the above example:
ppp0 refers to the PPP link interface and
enp6s0 to the ethernet interface that is connected to the Internet.
In order to resolve domain names on the Amiga 4000, I need to copy the nameserver settings from the
/etc/resolv.conf file of the desktop PC to the Amiga 4000.
After doing these configuration steps I can, for example, use
w3m to visit my homepage:
Exchanging files
Similar to my Amiga/Linux set up, I also want to the option to exchange files to and from my NetBSD/Amiga setup, for example, to try out stuff that I have downloaded from the Internet. For my NetBSD setup I can use the same two kinds of approaches.
Exchanging files with the memory card on my Linux PC
In my previous blog post I have shown that it is possible to take the Compact Flash card from my Amiga's CF2IDE device and put it in the card reader of my PC. Linux on my PC does not recognize an Amiga RDB partition table, but I can
use GNU Parted to determine the partitions' offsets and use a loopback device to mount it:
$ parted /dev/sdb
GNU Parted 3.6
Using /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) unit B
(parted) print
Model: Generic- USB3.0 CRW-CF/MD (scsi)
Disk /dev/sdb: 32019111936B
Sector size (logical/physical): 512B/512B
Partition Table: amiga
Disk Flags:
Number Start End Size File system Name Flags
1 56899584B 1130766335B 1073866752B asfs DH0 boot
2 1130766336B 1265338367B 134572032B netbsd-swap boot
3 1265338368B 3953166335B 2687827968B sun-ufs netbsd-root boot
4 3953166336B 6100899839B 2147733504B asfs DH1
5 6100899840B 8248633343B 2147733504B asfs DH2
6 8248633344B 16838664191B 8590030848B asfs DH3
7 16838664192B 32019111935B 15180447744B asfs DH4
(parted) quit
In the above code fragment, I have invoked GNU parted to read the partition table of my Amiga drive (
/dev/sdb), switched the units to bytes, and printed the partition table. The third partition entry (Number: 3) refers to the NetBSD root partition on my Amiga 4000.
Linux is capable of mounting UFS partitions. I can use the start offset and size fields in the above table to configure a loopback device (
/dev/loop0) referring to my Amiga drive's NetBSD partition:
$ losetup --offset 1265338368 --sizelimit 2687827968 /dev/loop0 /dev/sdb
Then I can mount the partition (through the loopback device file) to a directory:
$ mount /dev/loop0 /mnt/amiga-netbsd-partition
And then I can read files from the Amiga's NetBSD partition by visiting
/mnt/amiga-netbsd-partition. Unfortunately, my Linux kernel's UFS module does not seem to have write support enabled -- it appears that UFS write functionality is experimental and disabled by default. As a consequence, I can only read files from the partition.
When the work is done, I must unmount the partition and detach the loopback device:
$ umount /mnt/amiga-netbsd-partition
$ losetup -d /dev/loop0
I have also been investigating how I could exchange files with my PC if NetBSD were my desktop operating system. I learned that there is the
vndconfig command to configure a pseudo disk device (which is mostly feature comparable to a Linux loopback device), but I could not find any facilities to configure the partition offets.
Exchanging files between the AmigaOS and NetBSD operating systems
Similar to my Amiga Workbench 3.1/Linux hard drive configuration, I also want the ability to exchange files between my AmigaOS and NetBSD installation on the same system.
NetBSD on Amiga natively supports mounting Amiga Fast Filesystem partitions. For example, if I have such a partition I can automatically mount it on startup by adding the following line to
/etc/fstab:
/dev/wd0d /mnt/harddisk ados rw 0 0
As with my other Compact Flash card, I have picked
Smart Filesystem (SFS) over Amiga's Fast File system for the same reasons -- I need a file system that is more suitable for large hard drives. Unfortunately, it seems that there are no facilities for NetBSD to read from or write to Smart Filesystem partitions.
However, I can do the opposite --
a Berkeley Fast File System handler for AmigaOS seems to exist that offers read and write support.
Installing the package is similar to the
Ext2 handler described in the previous blog post:
- Unpacking the LhA file into a temp directory
- Copying the l/BFFSFileSystem file to L:
- Creating a DOSDriver mount entry to get the partition mounted.
Creating the DOSDriver mount entry was a bit tricky. I did the following steps:
- I used the doc/MountList.BFFS file from the LhA archive as a template by copying it to DEVS:DOSDrivers/BH0. In the destination file, I need to adjust a number of properties that we must look up first.
- I can use HDToolBox to determine the start and end cylinders of the NetBSD root partition.
- I can use SysInfo to determine the amount of surfaces and sectors per side, by opening the "DRIVES" function and selecting a random hard drive partition:
- Then I need to adjust the partition's DOSDriver file: DEVS:DOSDrivers/BH0:
- I must remove all examples, except the BH0: example
- The LowCyl and HighCyl need to match the properties that we have discovered with HDToolBox.
- The Surfaces property must match the value from SysInfo
- The BlocksPerTrack property must match the Sectors per side property in SysInfo.
- Finally I can make an icon for the BH0 DOS Driver, by copying the PC1.info file to BH0.info and removing the UNIT=1 tooltip (by using the icon information function).
The result is that I can access my NetBSD root partition from AmigaOS:
The screenshot above shows an Amiga Workbench 3.9 session in which I have opened the NetBSD root partition.
Running NetBSD/Amiga in FS-UAE
In my previous blog post, I have shown that it is also possible to install and run Linux in
FS-UAE, an Amiga emulator. Using an emulator is convenient for experimentation and running software at greater speeds than the real machine.
To run a different operating system, we must edit the FS-UAE configuration in a text editor and change the configuration to use a hard file. Moreover, we need to enable IDE emulation for the hard-drive and CD-ROM devices:
hard_drive_0 = mydrive.hdf
hard_drive_0_controller = ide
hard_drive_0_type = rdb
cdrom_drive_0_controller = ide1
The above configuration properties specify the following:
- We want to use a hard file: mydrive.hdf
- The controller property specifies that we need IDE controller emulation -- this property is required because NetBSD does not work with Amiga drivers. Instead, it wants to control hardware itself.
- The type property specifies that the hard drive image contains an RDB partition table. This property is only required when the hard file is empty. Normally, the type of a hard file is auto detected.
The result is that I can run NetBSD conveniently in FS-UAE:
As with my Linux installation, I can also take the Compact Flash card in my Amiga's CF2IDE drive (containing the NetBSD installation), put it in the card reader of my PC and use it in FS-UAE.
I need to change the hard drive setting to use the device file that corresponds to my card reader:
hard_drive_0 = /dev/sdb
In the above code fragment:
/dev/sdb corresponds to the device file representing the card reader. I also need to make sure that the device file is accessible by an unprivileged user by giving it public permissions, by running the following command (as a root user):
$ chmod 666 /dev/sdb
Conclusion
In this blog post I have shown how I have been using NetBSD on my Amiga 4000. I hope this information can be of use to anyone planning to run NetBSD on their Amigas.
Compared to running Linux on Amiga, there are pros and cons. I definitely consider the homepage and documentation of NetBSD's Amiga port to be of great quality -- all required artifacts can be easily obtained from a single location and the installation procedure is well documented.
Moreover, NetBSD 10.1 (released in December 2024) is considerably newer than Debian 3.1r8 (released in 2008) and provides more modern software packages. Furthermore, the X Window System in NetBSD supports the Amiga chipset for displaying graphics -- the Debian Linux version does not.
NetBSD also has a number of disadvantages. Foremost, I consider its biggest drawback its speed -- it is considerably slower than my Debian Linux installation. This is probably due to the fact that modern software is slower than older software, not because Linux is superior to NetBSD when it comes to speed. Most likely, if I can manage to make a modern Linux distribution work on my Amiga, then it would probably also be much slower than Debian 3.1r8.
Another drawback is that I have much fewer options to control the framebuffer in NetBSD. With Linux I can easily select the video output device, resolutions and color modes at boot time and run time. In NetBSD the options are much more limited.
Beyond these observable Amiga differences between NetBSD and Linux, there are many more differences between NetBSD and Debian Linux, but I will not cover them in this blog post -- this blog post is not a NetBSD vs Linux debate.
Finally, I want to say that I highly appreciate the efforts of the NetBSD developers to have improved their Amiga port. NetBSD is definitely usable and useful for the Amiga. It would be nice if some areas could be improved even further.